Our mission is to conduct world-leading research on the use of high-level specifications and models for design and analysis of software, bridging the gap between theory and applications.
Software has shaped every aspect of our modern lives, including our work, our communication, our social life, our transportation, our financial systems, our healthcare, and even our food production. Providing programmers with tools that elevate their productivity, simplify code maintenance, and ensure that software is correct, efficient, dependable and sustainable, is both a major scientific challenge and an enterprise with enormous societal relevance. How can we be sure that large computer programs are correct? What does correctness mean anyway? How can we build software that we can trust and depend on, software that is reliable, available, safe and secure? Can we define programming languages in which it is easy to describe certain complex tasks, and have a computer perform these tasks efficiently? In our research we address these questions.
Modelling is an essential part of many scientific and engineering disciplines. Our group studies (mathematical) models for the design and analysis of software. Here a model is defined as any description of a system that is not the thing-in-itself (das Ding an sich in Kantian philosophy). We study software models both from an engineering perspective ("Can we build a computer-based system whose behavior matches that of a given model?") and from a science perspective ("Can we build a model whose behavior matches that of a given computer-based system?"). We believe that both perspectives are crucial, and that by properly combining them we can build better software. Our research belongs to the area of Computer Science commonly referred to as formal methods, and contributes to the field of model-based software engineering in which models are the primary artifact during software construction.
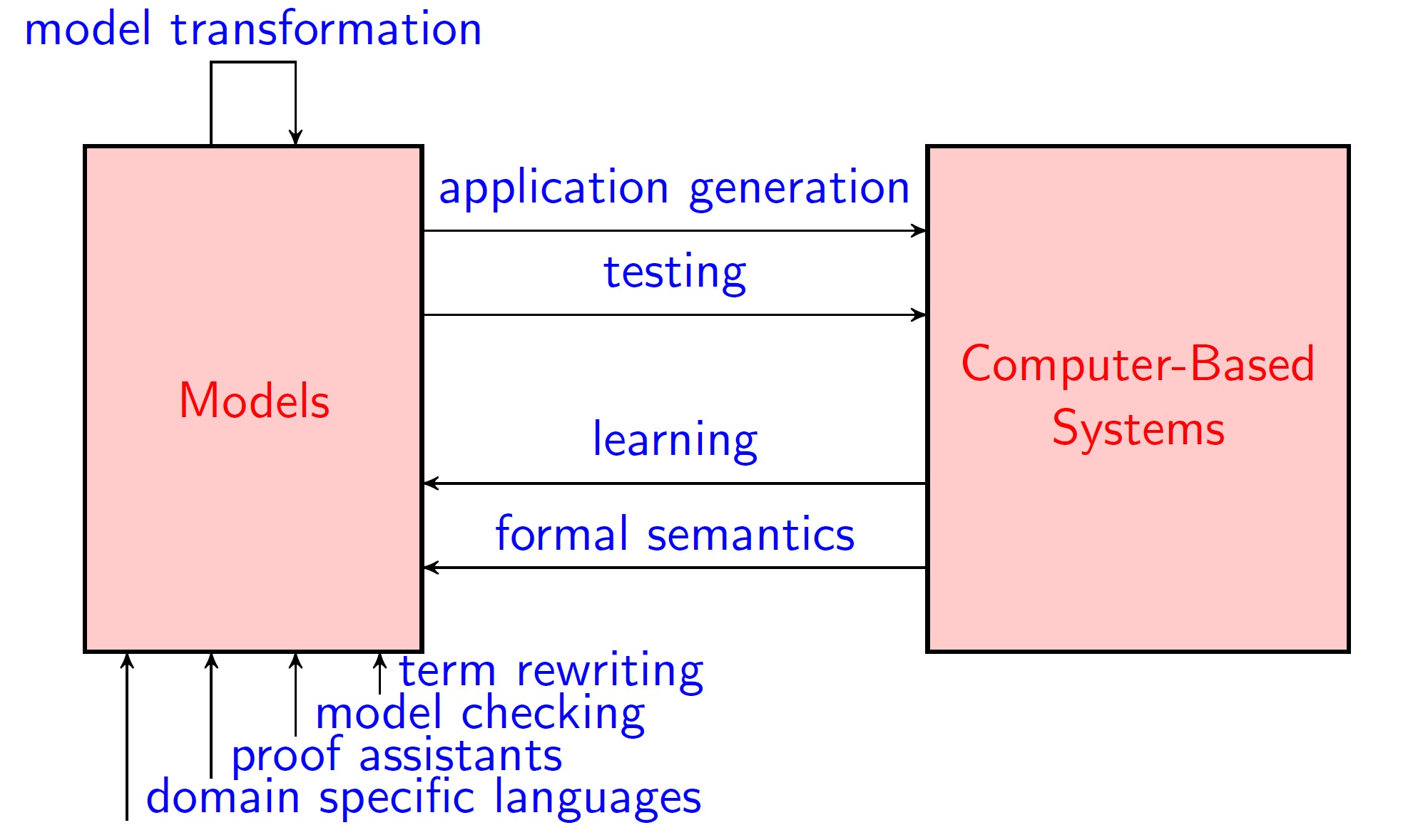
Engineering models of software can be defined by domain experts using domain specific languages, and modified automatically using model transformations. In our research, we study the design of domain specific languages for parallel en task-based programming, and the challenge to generate code fully automatically from high-level models. Our goal is to reduce software development time and increase system reliability and performance. Domain specific languages must possess powerful abstraction mechanisms enabling to abstract from low level details. For this reason it is sometimes better to embed these language in an advanced general purpose programming language. This also makes it easier to extend the modeling language with new constructs. For over two decades, Nijmegen has maintained a leading role in the development of efficient functional programming languages.
Systematic testing is important for software quality, but it is also error prone, expensive, and time-consuming. Our group is known for pioneering work on model-based testing, a technology that can improve the effectiveness and efficiency of the testing process. In model-based testing, the goal is to automatically test whether the behavior of a computer system conforms to the behavior of a given (engineering or scientific) model.
A new research area - in which our group is at the forefront internationally - is to develop machine learning algorithms that automatically construct (scientific, behavioral) models of computer systems by observing their behavior. These model learning algorithms can be used, for instance, to find bugs in implementations of network protocols. We can also use a learned (scientific) model of a legacy software component to check conformance of a refactored implementation.
With rapidly growing application of artificial intelligence (AI) and machine learning, the need for verified dependability and safety guarantees of AI systems against potentially fatal flaws is self-evident. An important question is then, how confidence in system behaviors obtained from machine learning can be obtained using established techniques from formal methods research such as (probabilistic) model checking. Vice versa, when we apply formal methods to challenging applications, e.g., from industry, scalability often is a key issue. Leveraging the capabilities of machine learning to assess large data sets will make it easier to design, build and analyze realistic systems.
For many programming languages that are widely used, the semantics of certain language features is not at all clear. Our group has defined formal semantics for the programming languages such as C and Rust, and uses proof assistants to establish key properties of the resulting semantic models. Our group has a strong reputation in studying the mathematical foundations of software modelling frameworks (e.g., type theory, concurrency theory, and co-algebras), and techniques and tools to analyze software (e.g., term rewriting).
We find it important (and inspiring!) to cover the full spectrum from theory to applications in a single research group. Through collaboration with stakeholders from industry and society, we obtain a better understanding of when and how software science can help to solve real-world problems. Working together with our partners, using the Industry-as-Laboratory approach, also allows us to identify important new scientific challenges to work on. Some members of our group primarily focus on applications, other members focus on software tools, and a few just do theory. Our goal is always to have chains of collaboration all the way from theory to practical application.